

NVIDIA on Brev
NVIDIA x Brev NIMs Hackathon
Let's launch NVIDIA's Llama3 NIM on Brev. This is still in early access!
This documentation was referenced and intended for the Llama3 NIM Hackameetup hosted by Brev.dev & NVIDIA in May 2024. For more up to date info, please check out this link.
1. Create an account
Make an account on the Brev console.
2. Redeem your credits
We'll have the redemption code to get compute credits in your account at the hackathon! Reach out to a Brev team member if you need help finding this. You'll need to redeem your credits here before you can progress.
3. Launch an instance
We've set 2 ways to deploy a NIMs instance; an easy way and a more advanced way.
The easy way is to click this Launchable and to run through the notebook that gets launched. The notebook will walk you through the process of fine-tuning Llama3 with DPO and demonstrate how the NIM deploys it for you!
The advanced way takes a few more steps, but gives you more clarity on how to set up your own NIMs instance. To begin, head over to the Instances tab in the Brev console and click on the green Create Instance for NIMS Hackathon button.

To deploy the Llama3 NIM, we recommend using either an A100 or L40S GPU during the hackathon!
Once you've selected your GPU, you'll need to configure the instance container settings. Click on Advanced Container Settings and then click the slider to enable VM-only mode.

Now, enter a name for your instance and click on the Deploy button. It'll take a few minutes for the instance to deploy - once it says Running, you can access your instance with the Brev CLI.
4. Connect to your instance
Brev wraps SSH to make it easy to hop into your instance, so after installing the Brev CLI, run the following command in your terminal.
To SSH into your VM and use default Docker:
brev shell <instance-name> --host
5. Time to deploy your first NIM!
We've already authenticated your instance with NVIDIA's Container Registry.
First, let's choose a container name for bookkeeping
export CONTAINER_NAME=meta-llama3-8b-instruct
Grab the Llama3-8b-instruct NIM Image from NGC
export IMG_NAME="nvcr.io/mphexwv2ysej/${CONTAINER_NAME}:24.05.rc7"
Choose a system path to cache downloaded models
export NGC_HOME=${NGC_HOME:-~/nim-cache}
mkdir -p $NGC_HOME && chmod 777 $NGC_HOME
Run our tunnel setup script
sh ~/.tunnel-setup.sh
Start the LLM NIM
docker run -ti --rm --name=meta-llama3-8b-instruct \
--gpus all \
-e NGC_API_KEY=$NGC_API_KEY \
-e NIM_MODEL_NAME=nvcr.io/mphexwv2ysej/meta-llama3-8b-instruct \
-e NIM_MODEL_PROFILE=15fc17f889b55aedaccb1869bfeadd6cb540ab26a36c4a7056d0f7a983bb114f \
-v $NGC_HOME:/home/nvs/.cache \
-p 8000:8000 \
nvcr.io/mphexwv2ysej/meta-llama3-8b-instruct:24.05.rc7
Note: if you face permission issues, re-try using sudo.
Let's run the NIM!
The NIM is set to run on port 8000 by default (as specified in the above Docker command). In order to expose this port and provide public access, go to your Brev.dev console. In the Access tab in your instance details page, scroll down to Using Tunnels to expose Port 8000 in Deployments.
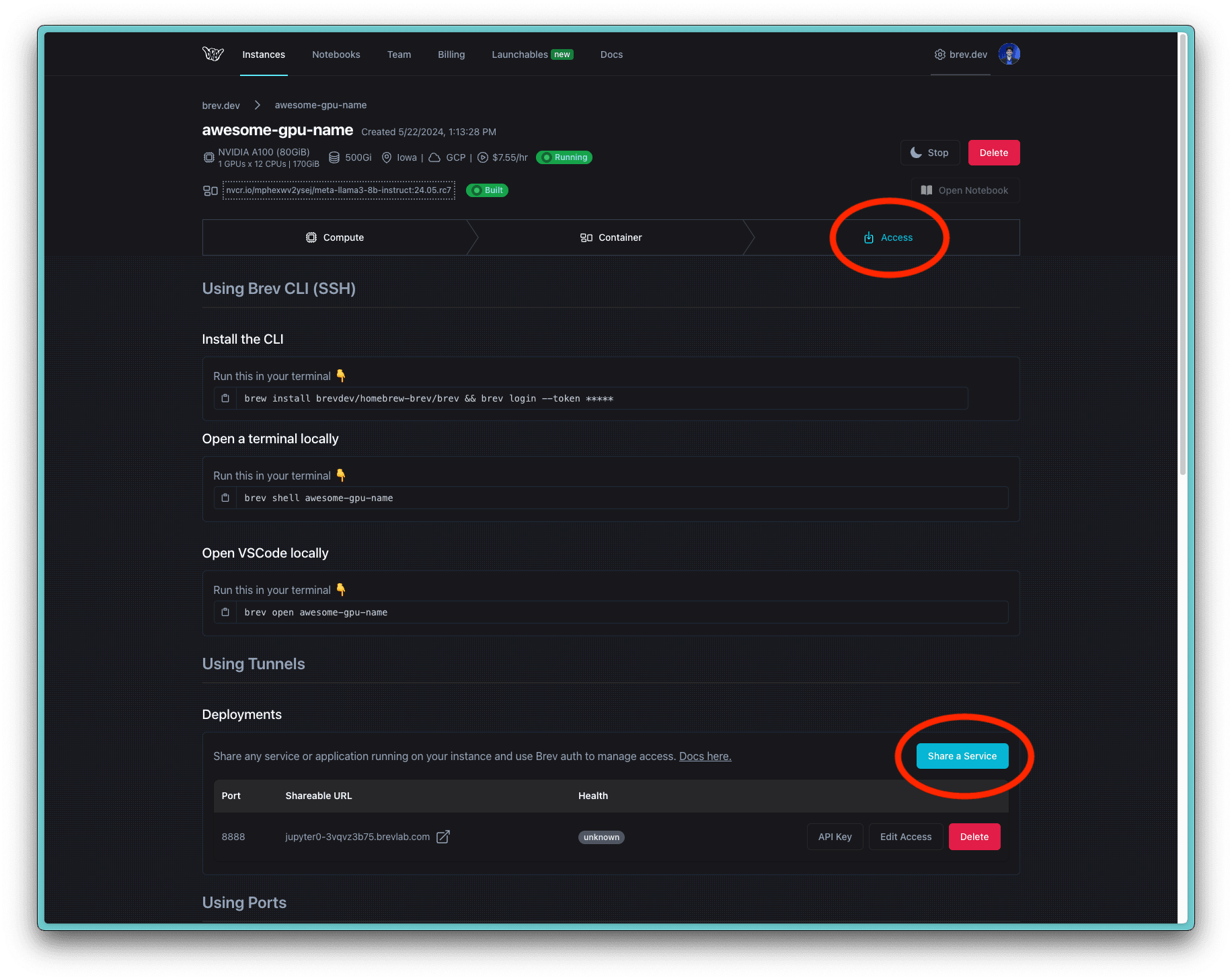
Click on the URL to copy the link to your clipboard - this URL is your <brev-tunnel-link>.
Run the following command to prompt Llama3-8b-instruct to generate a response to "Once upon a time":
curl -X 'POST' \
'<brev-tunnel-link>/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta-llama3-8b-instruct",
"prompt": "Once upon a time",
"max_tokens": 225
}'
You can replace /vi/completions with /v1/chat/completions, /v1/models, /v1/health/ready, or /v1/metrics!
You just deployed your first NIM! 🥳🤙🦙
Working with NIMs gives you a quick way to get production-level, OpenAI API specs during your testing/iteration process. Even with this early access Llama3 NIM, it's easy to see how powerful and fast running this model is! Stay tuned for even more guides using NVIDIA NIMs 🥳🤙🦙